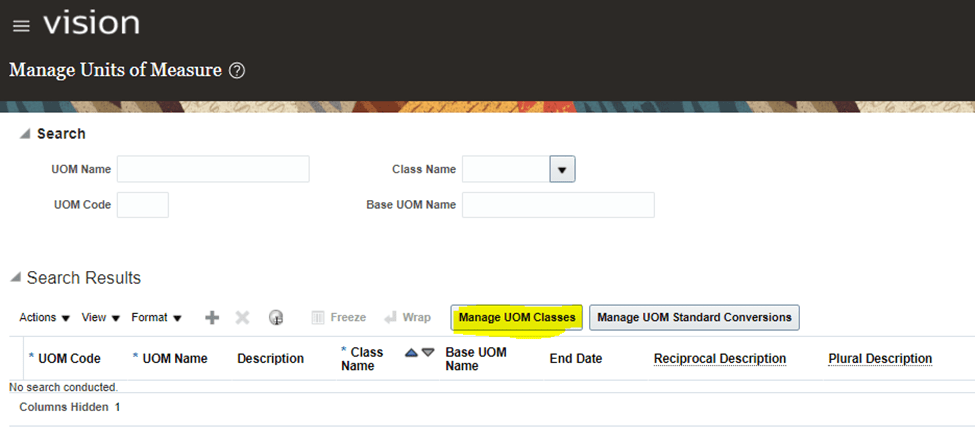
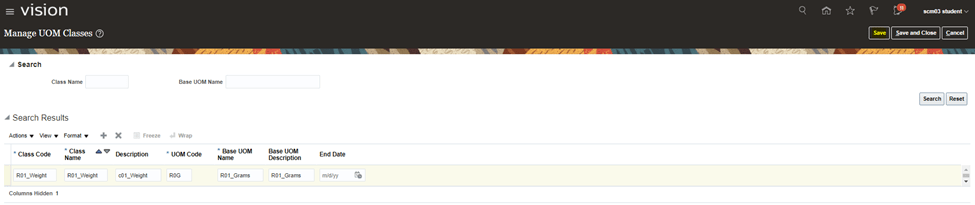
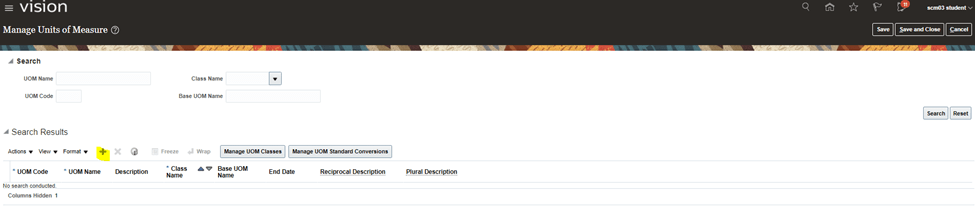
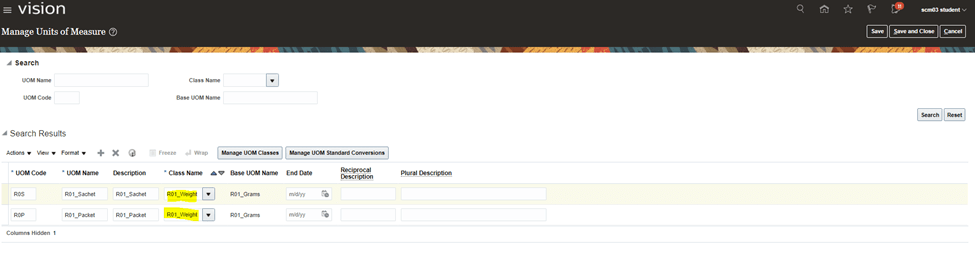
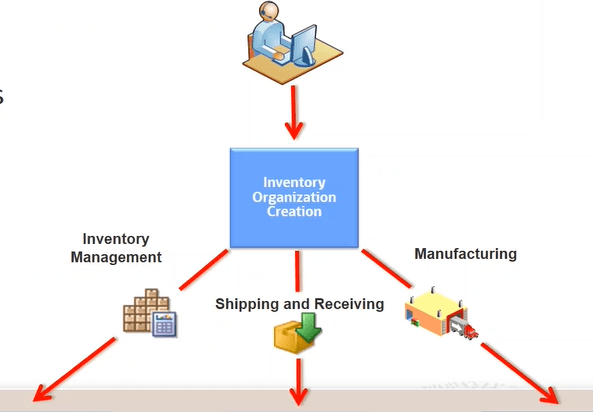
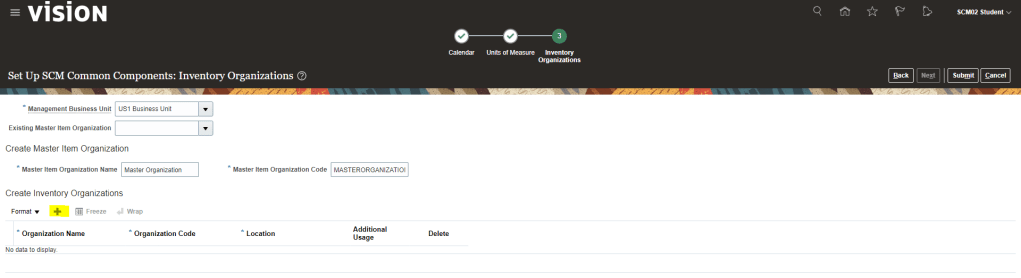
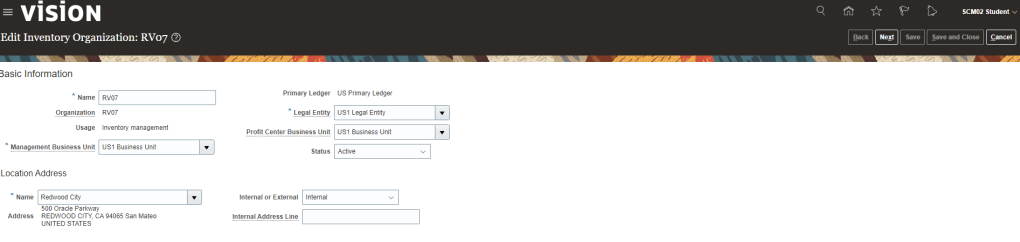
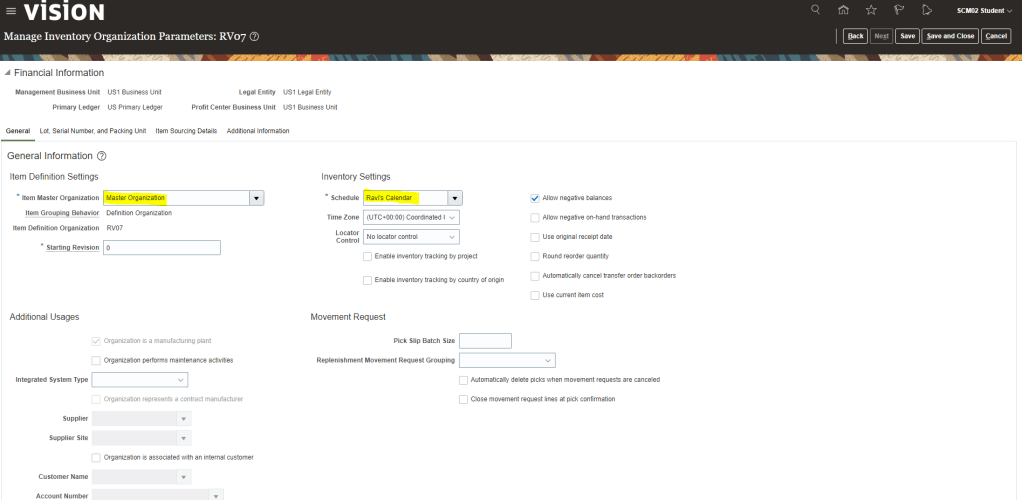
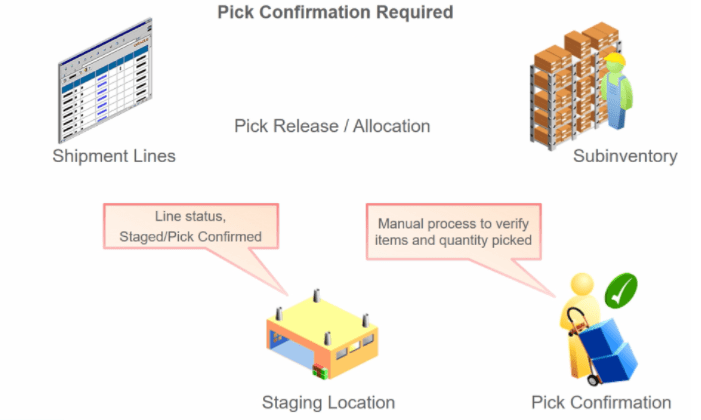
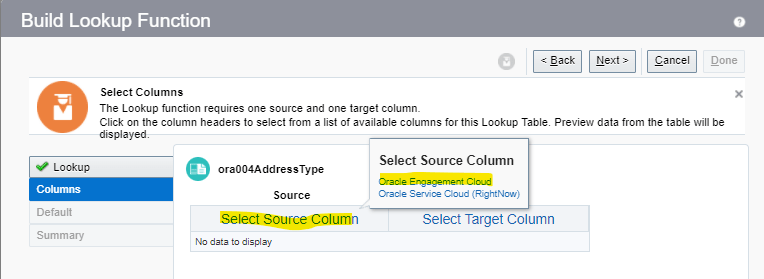
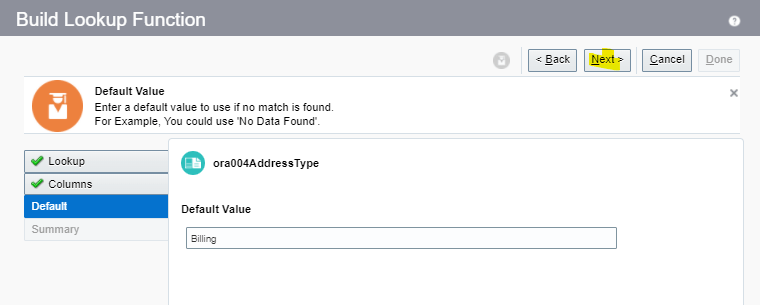
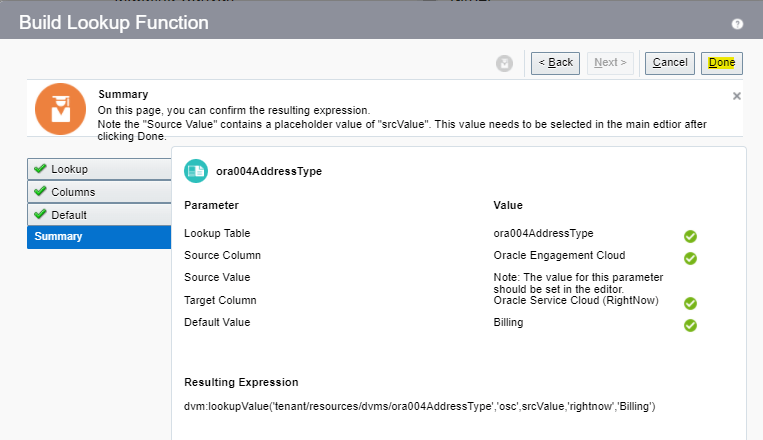
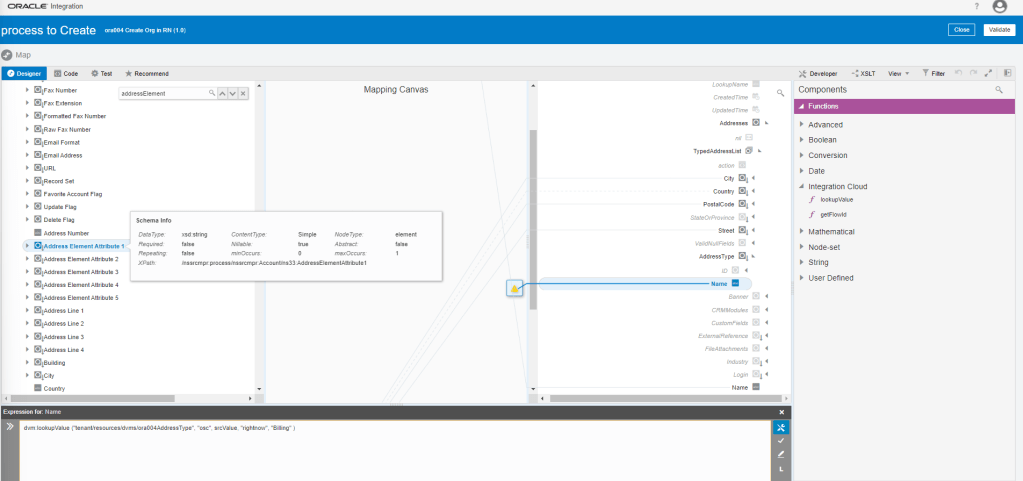
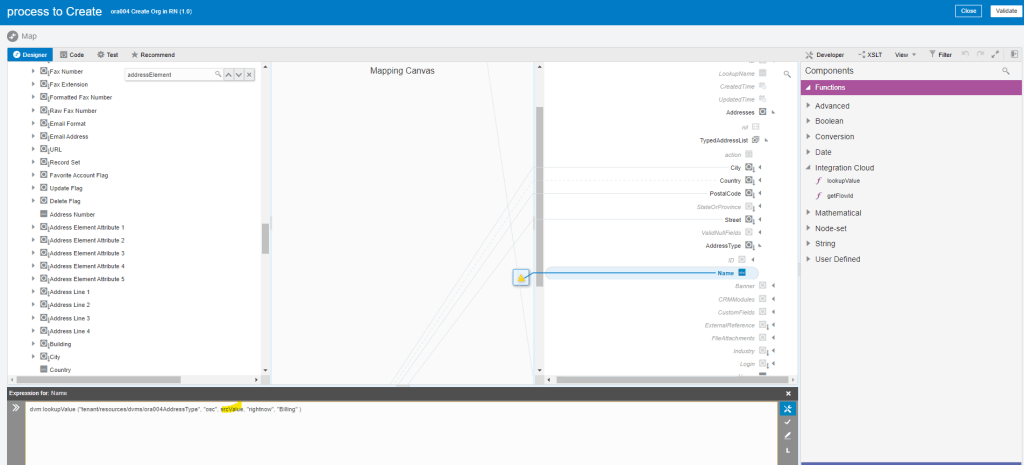
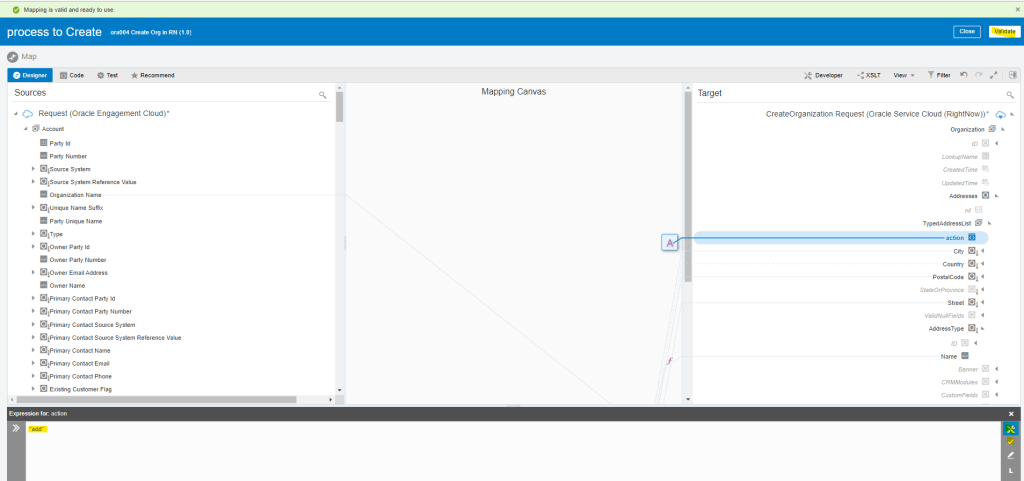
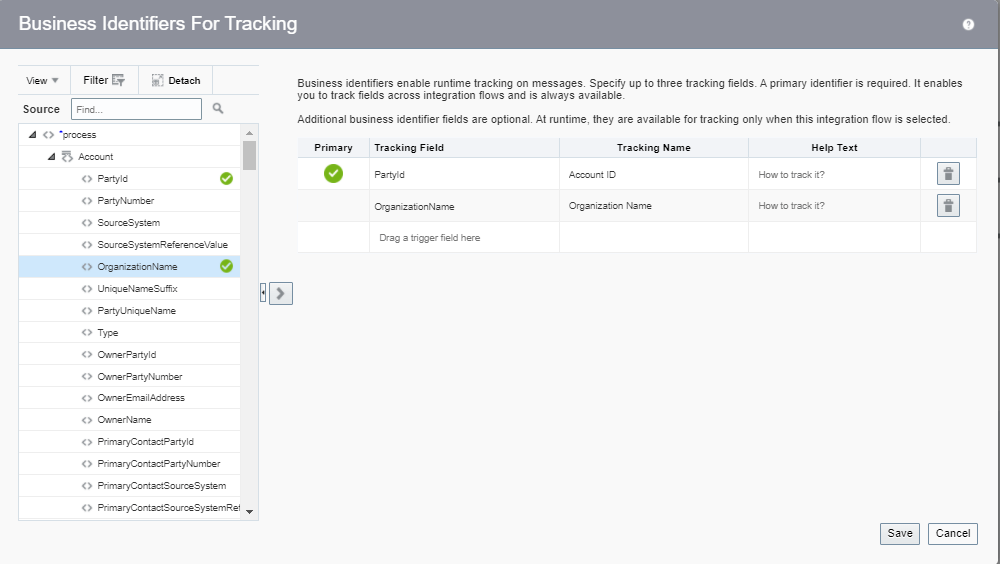
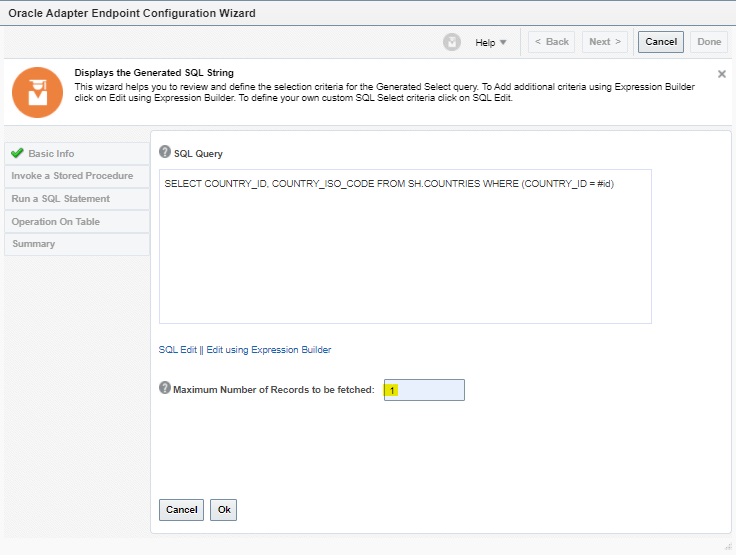
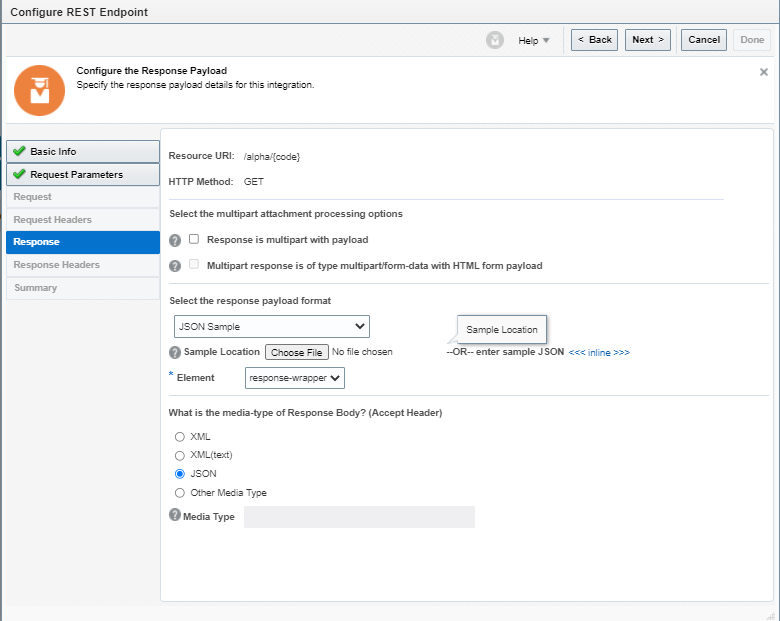
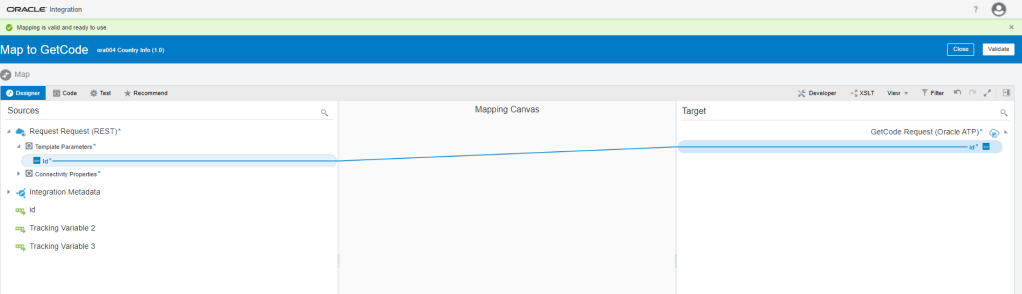
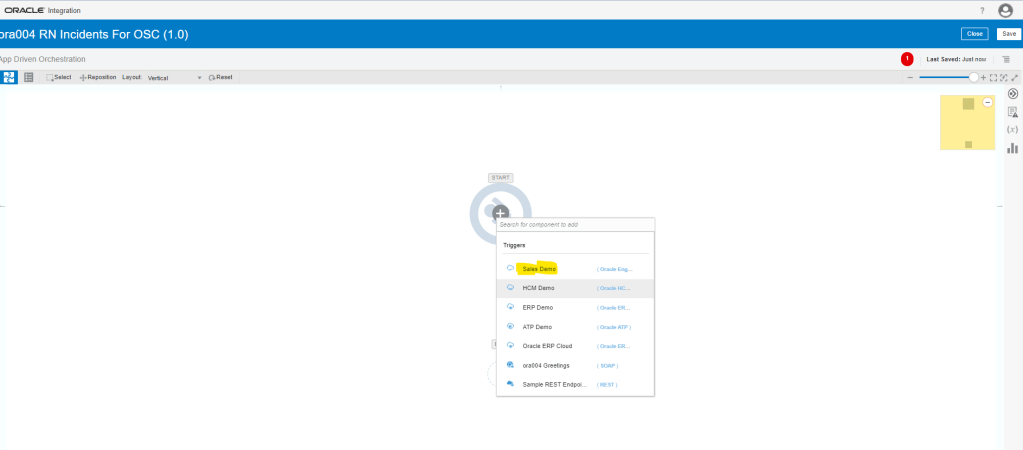
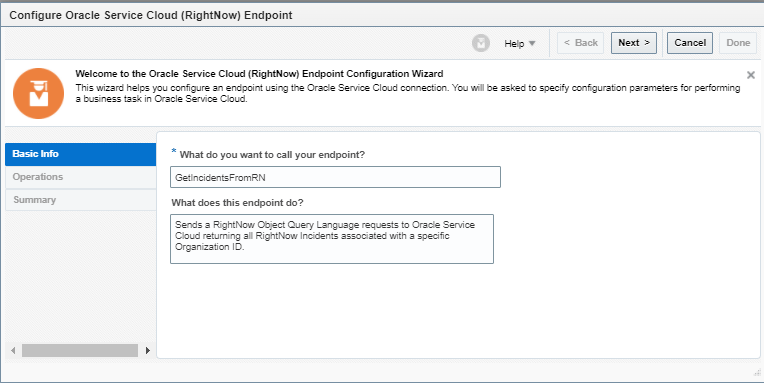
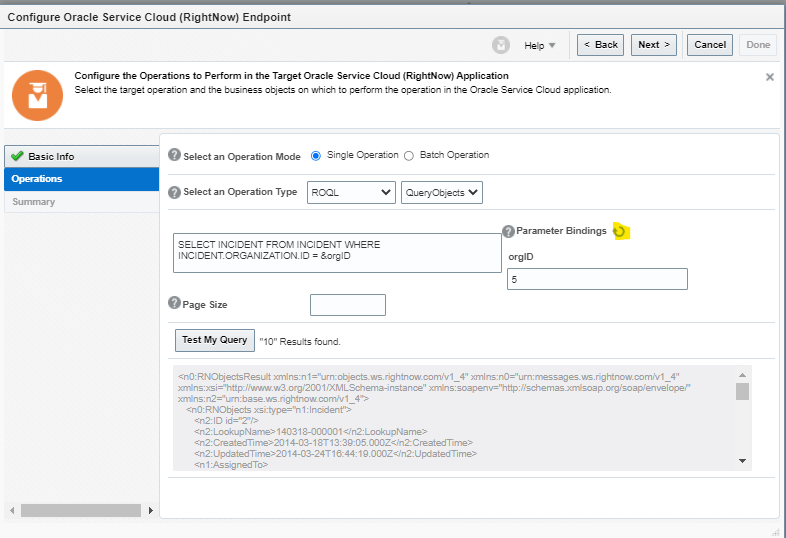
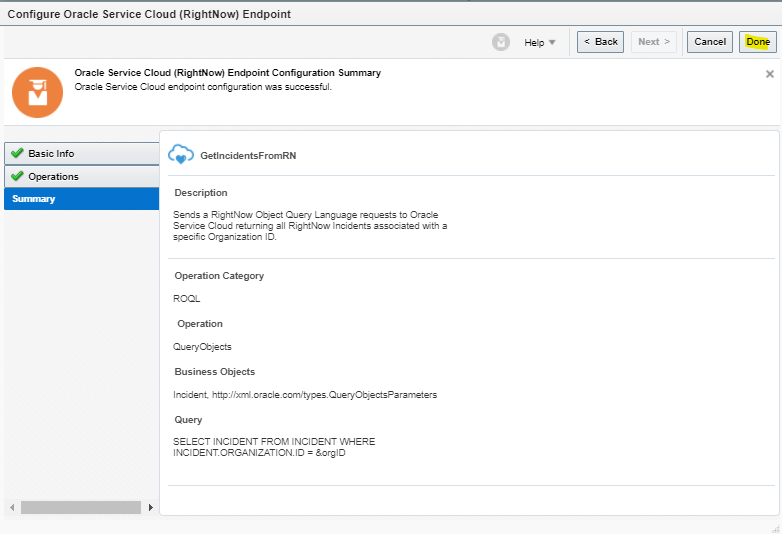
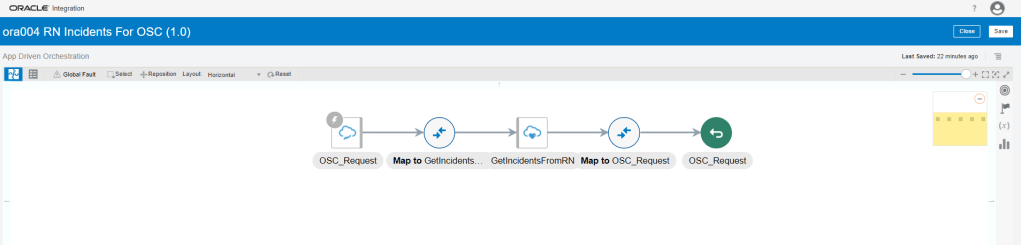
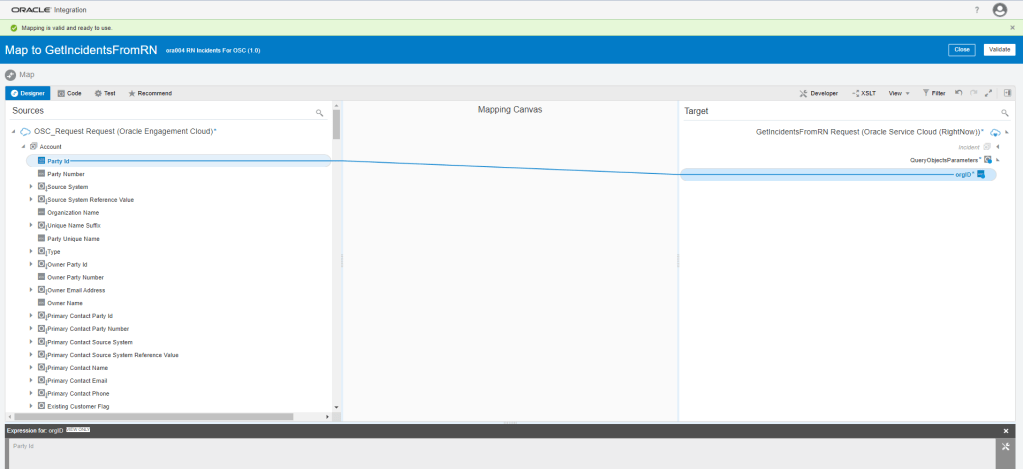
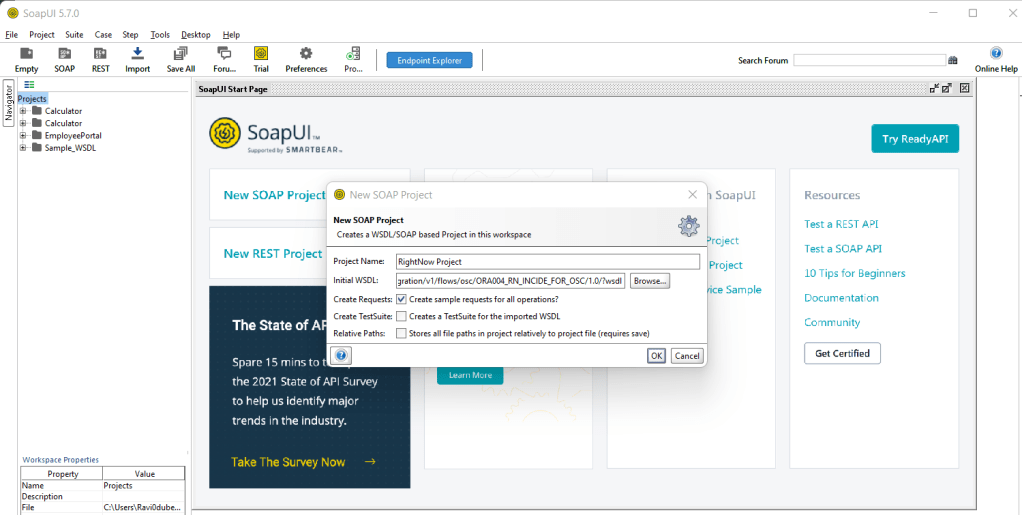
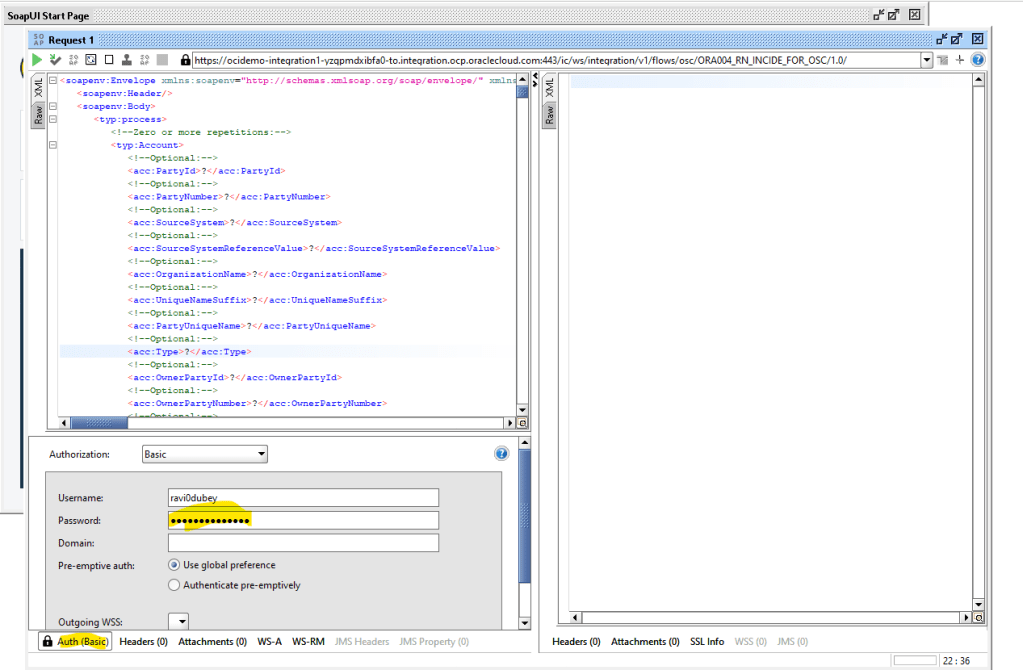
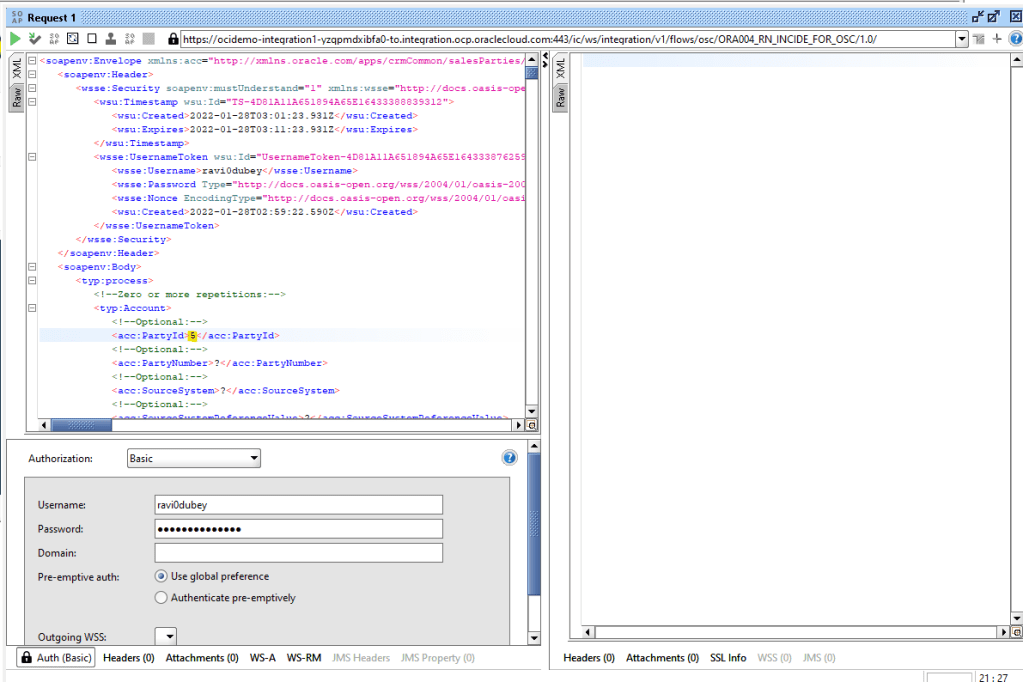
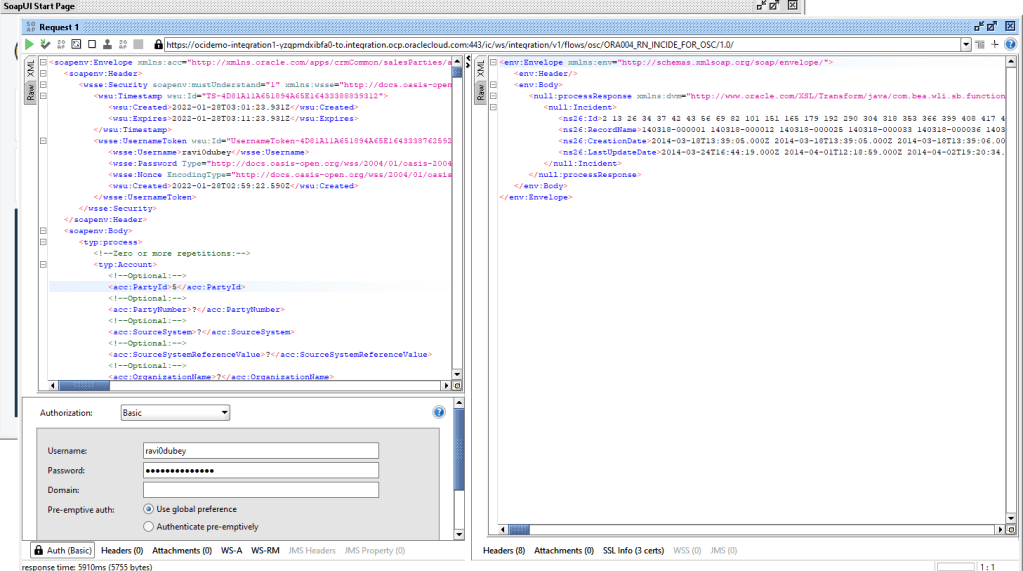
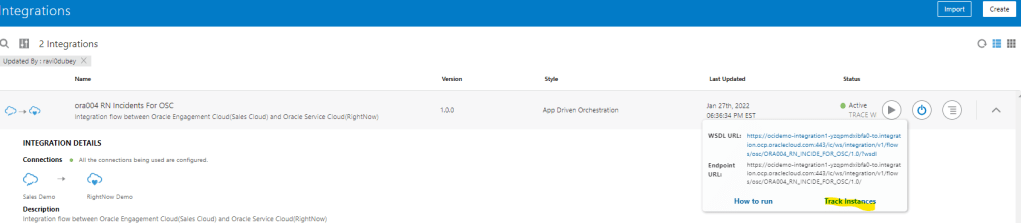
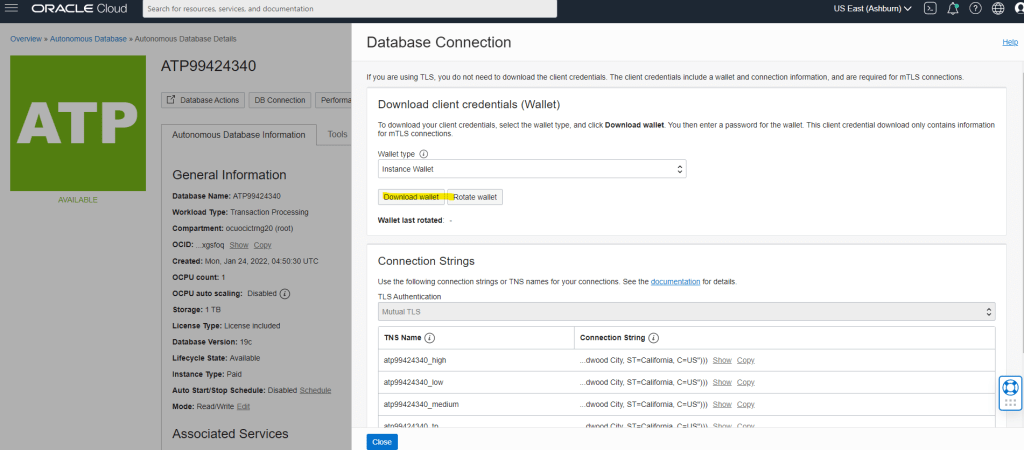
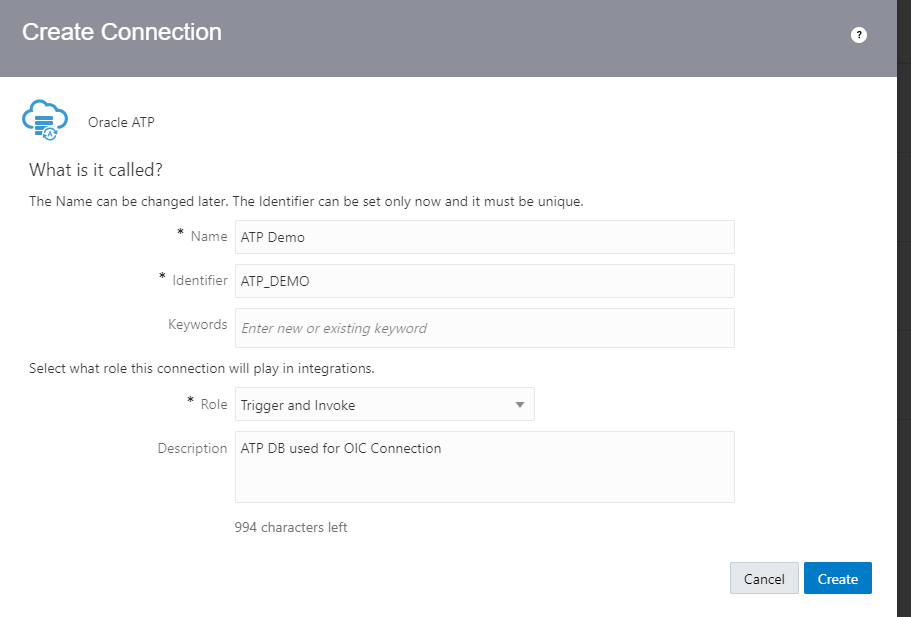
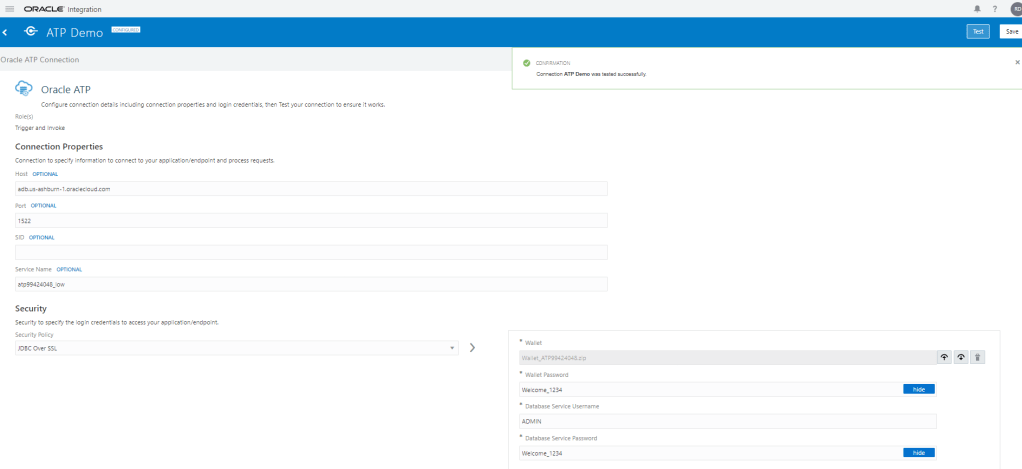
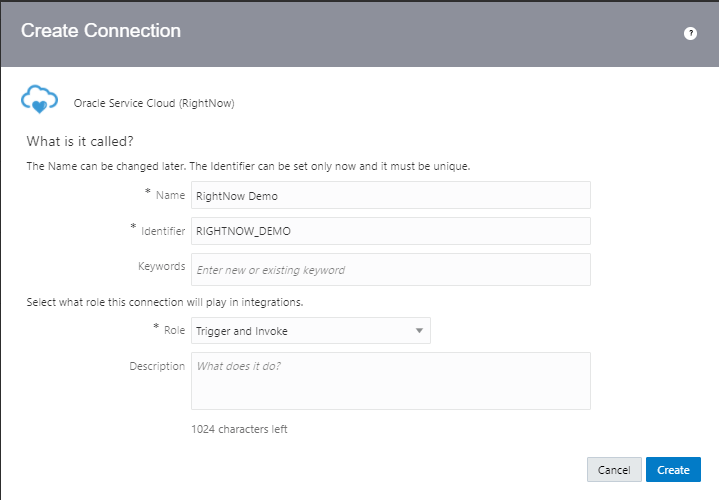
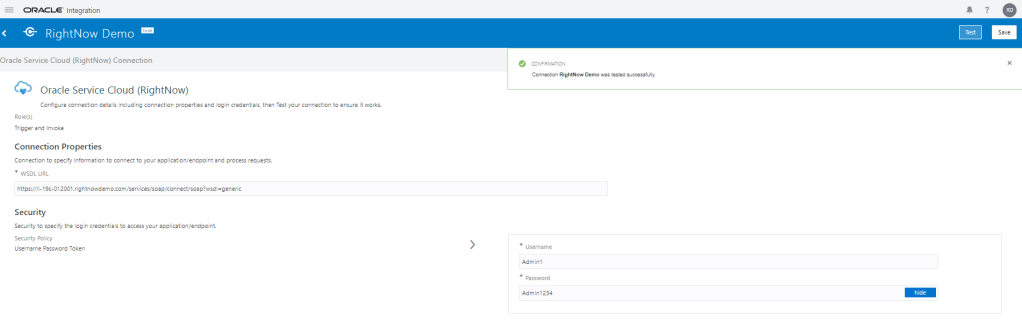
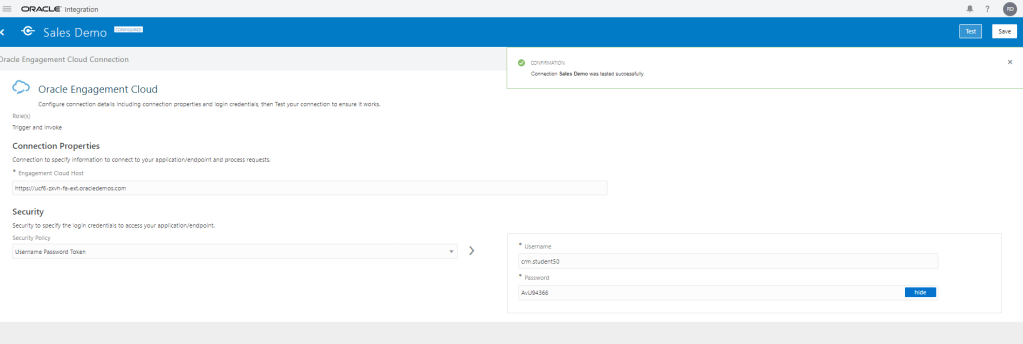
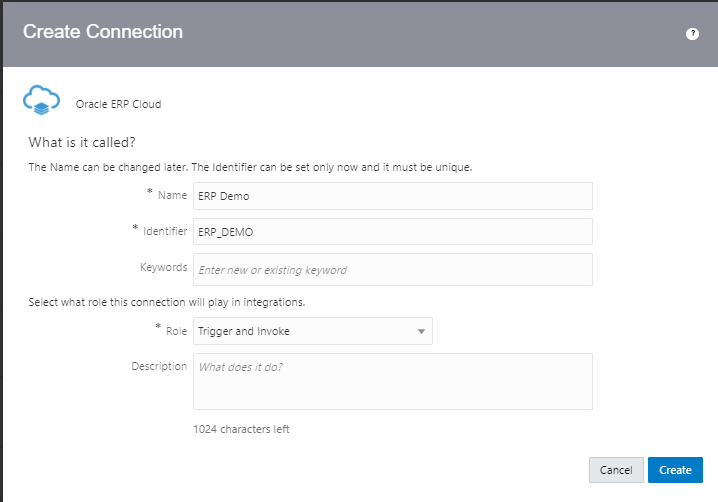
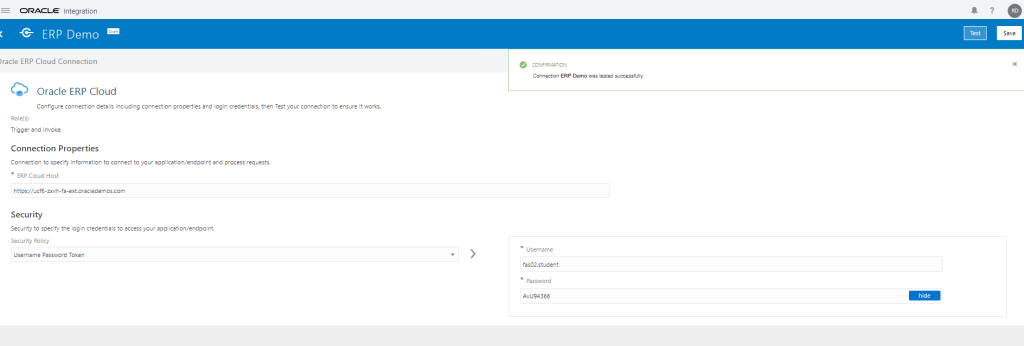
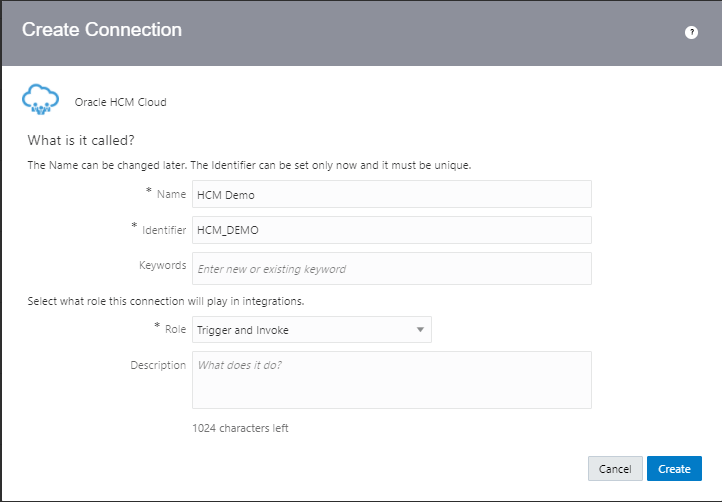
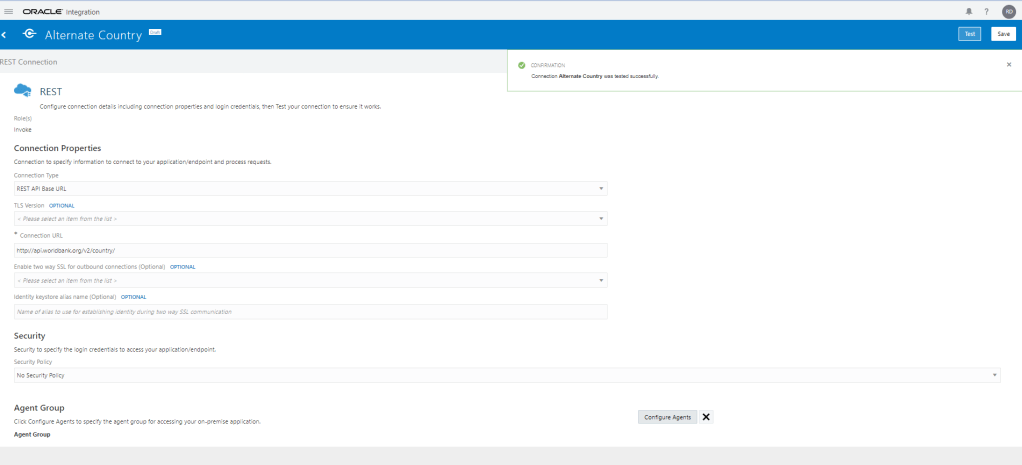
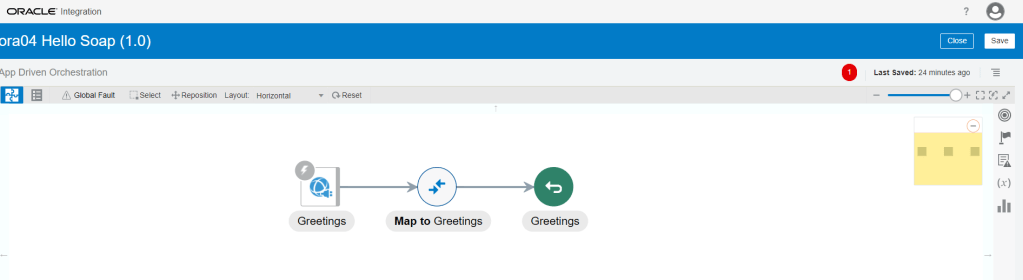
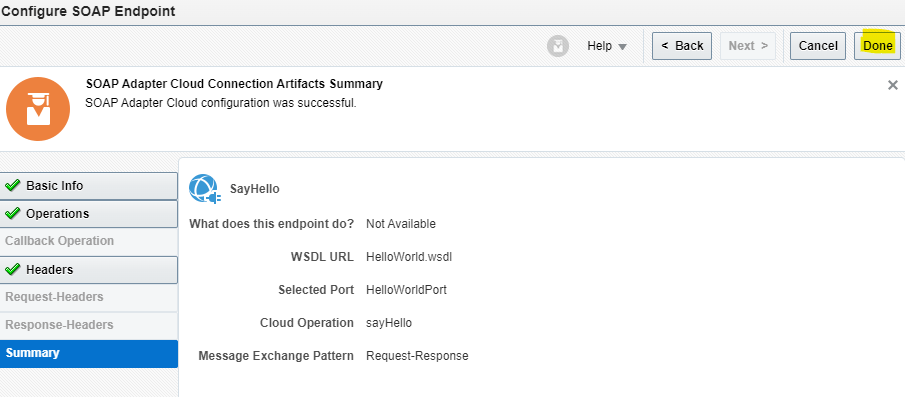
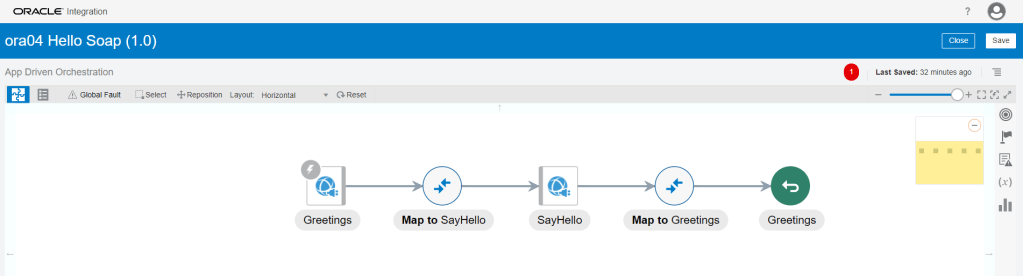
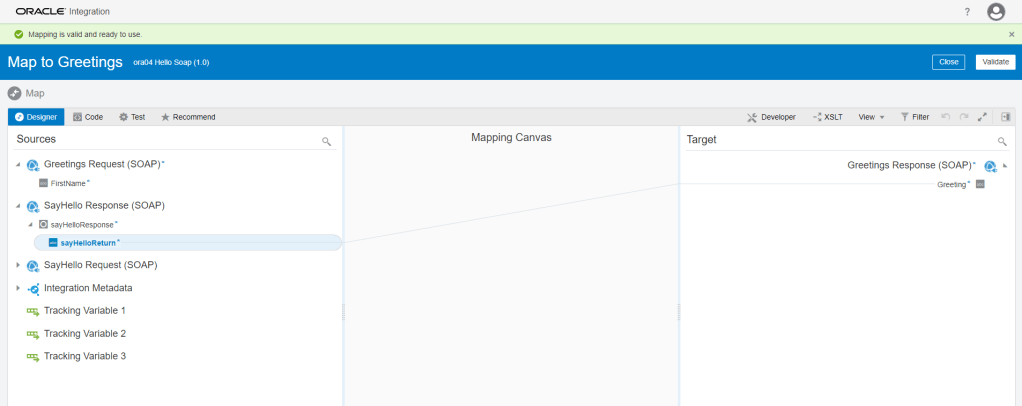
Encoding is a technique of converting categorical variables into numerical values so that it could be easily fitted to a machine learning model.
Before getting into the details, let’s understand about the different types of categorical variables.
- Nominal Categorical
- Ordinal Categorical
Nominal Categorical Variable:
Nominal categorical variables are those for which we do not have to worry about the order of the categories.
Example,
i. suppose we have a gender column with categories as Male and Female.
ii. We can also have a state column in which we have different states like NY, FL, NV, TX
Ordinal Categorical Variable:
Ordinal categorical variables are those for which we have to worry about the order of the categories.
Example,
i. Education Degrees, it starts with “High School”, “Graduate”, “Master”, and “P.H.D”
If we are filling Education details of a person It has to start from highest education to Lowest or Lowest to Highest. It cannot be entered randomly.
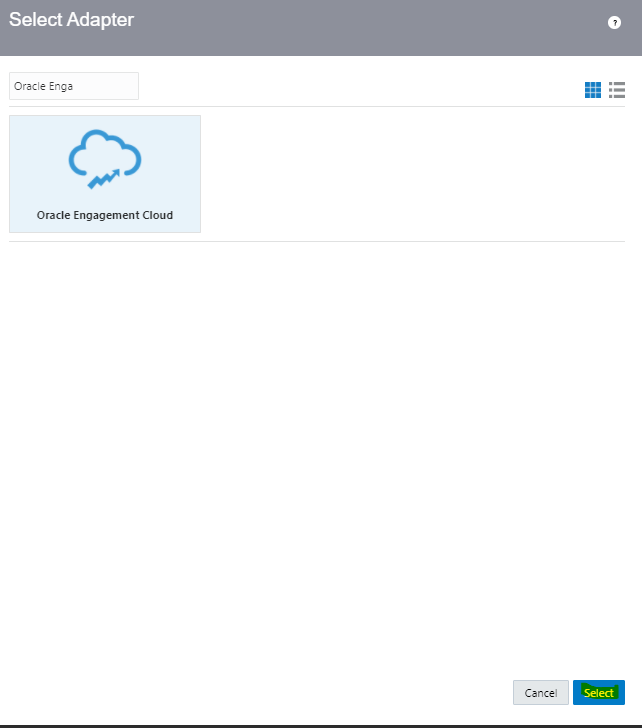
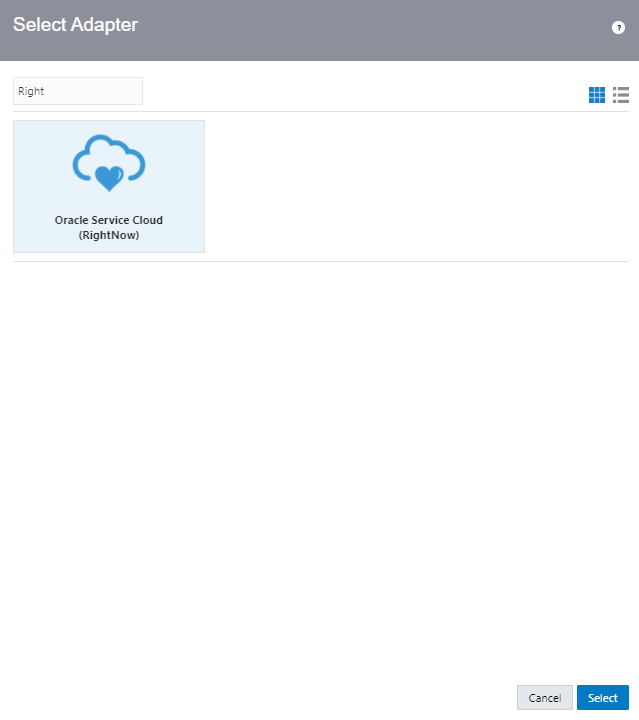
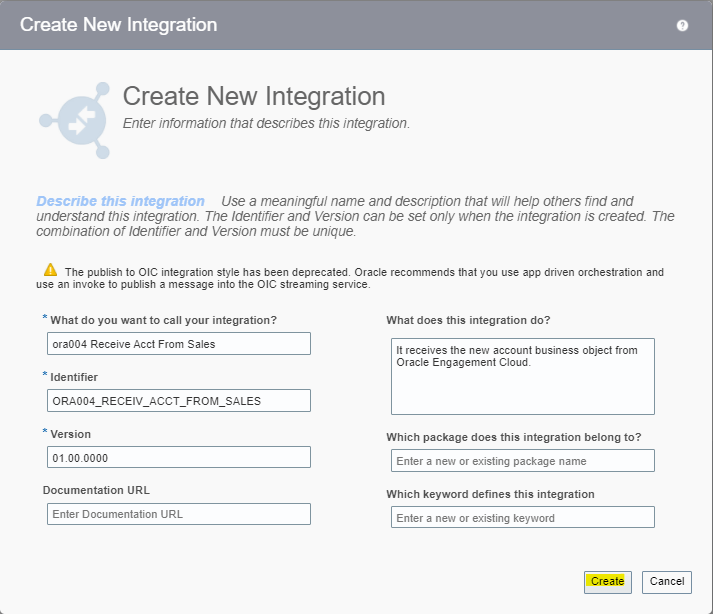
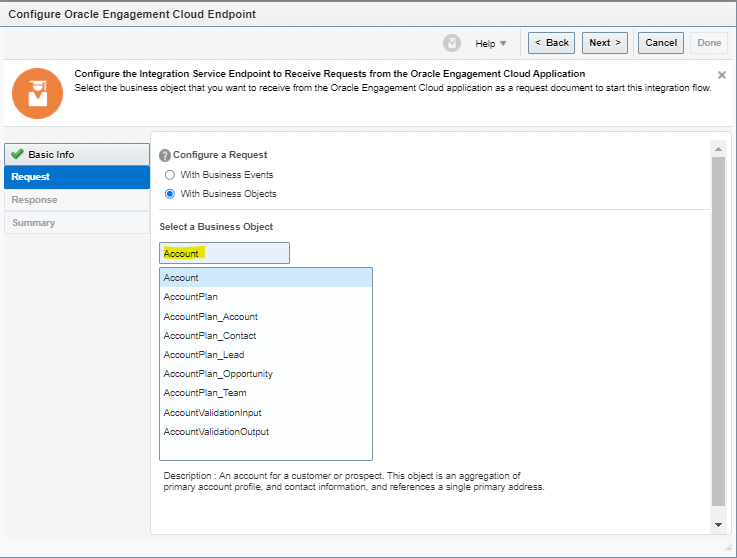
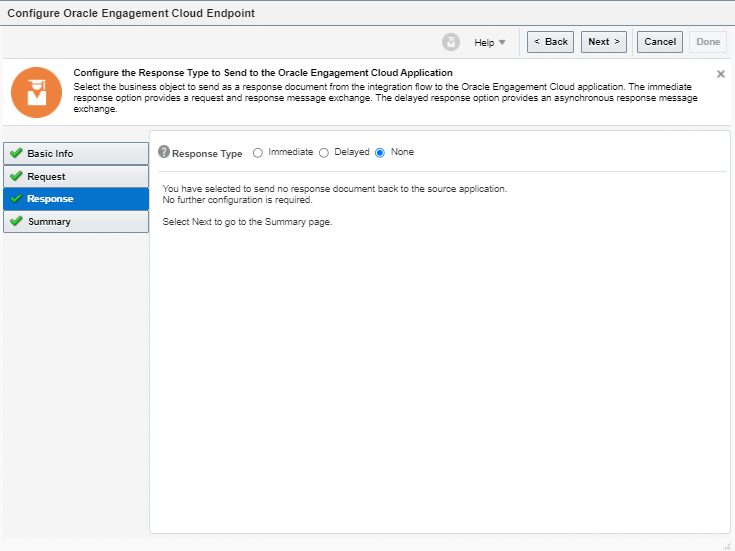
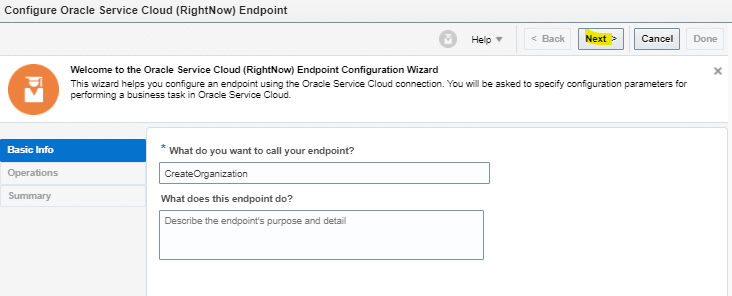
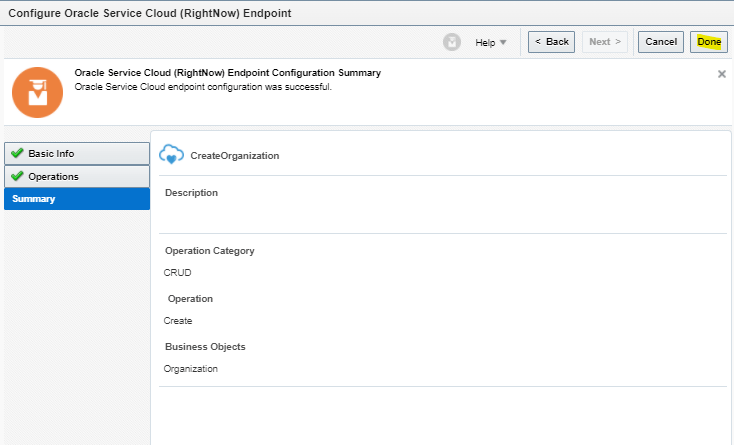
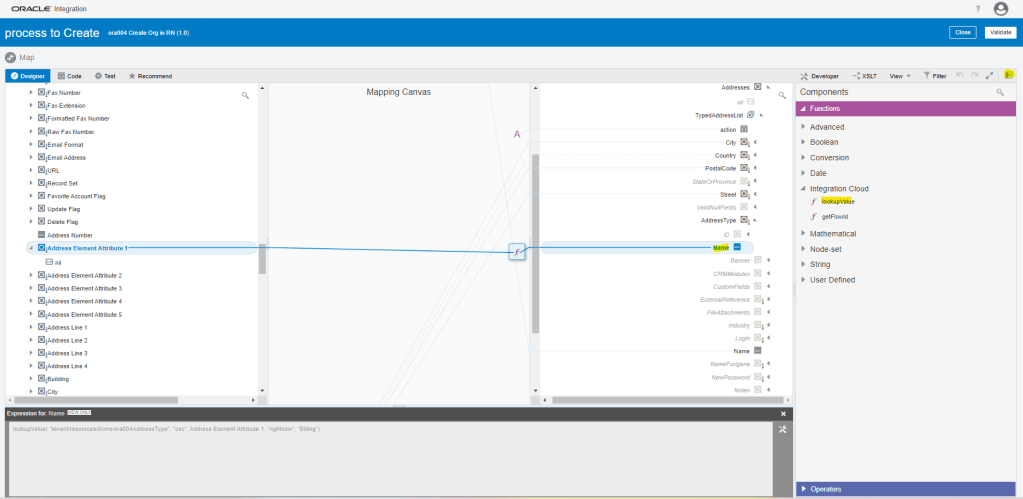
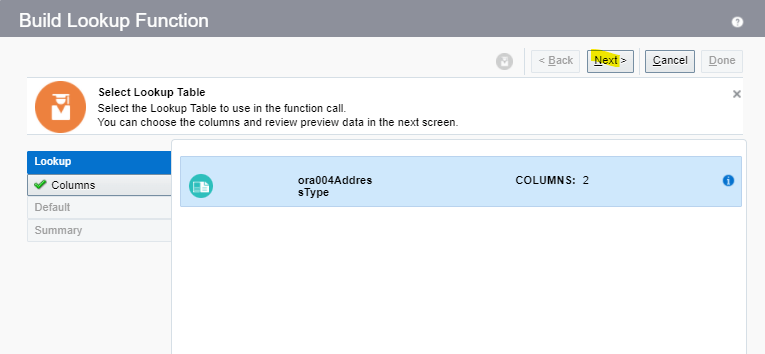
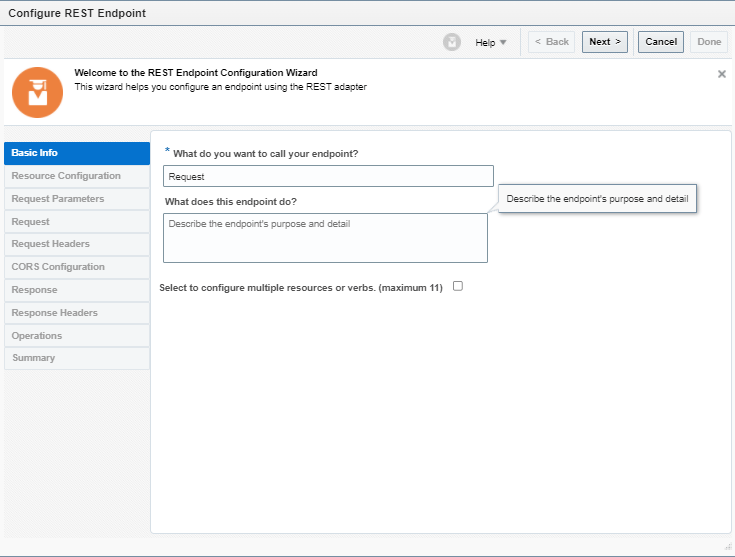
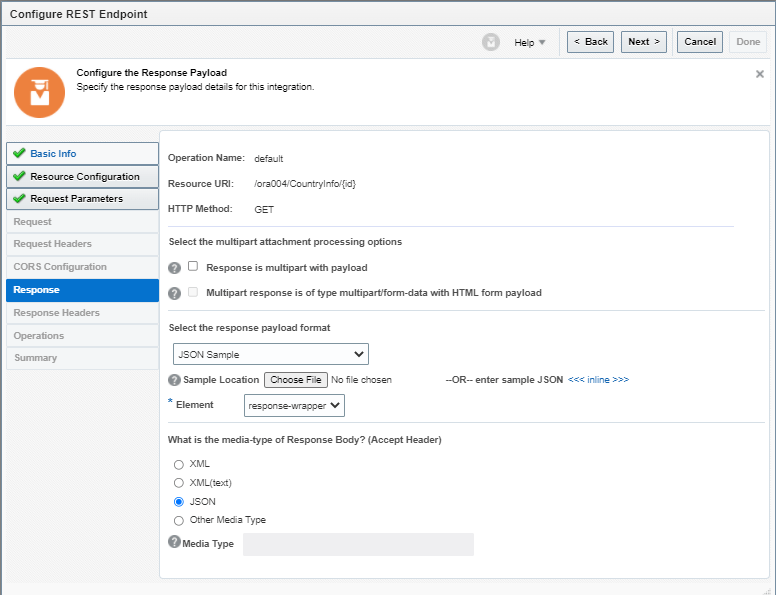
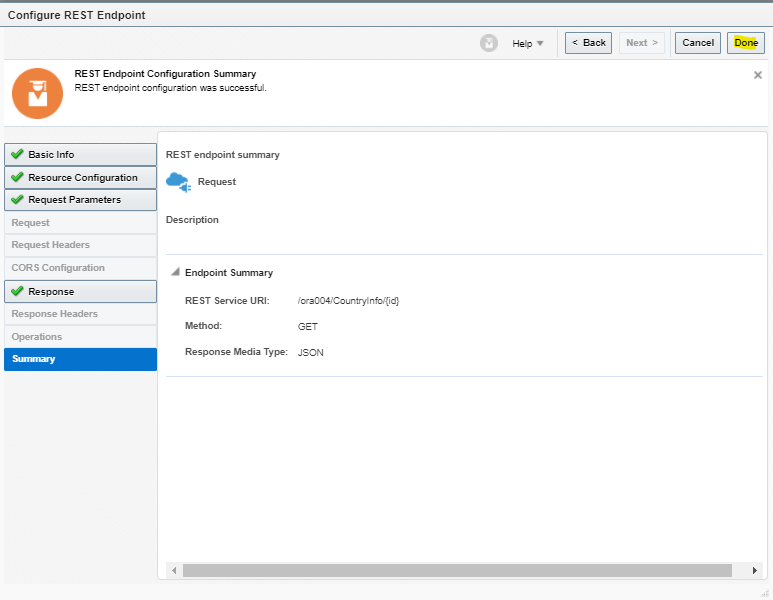
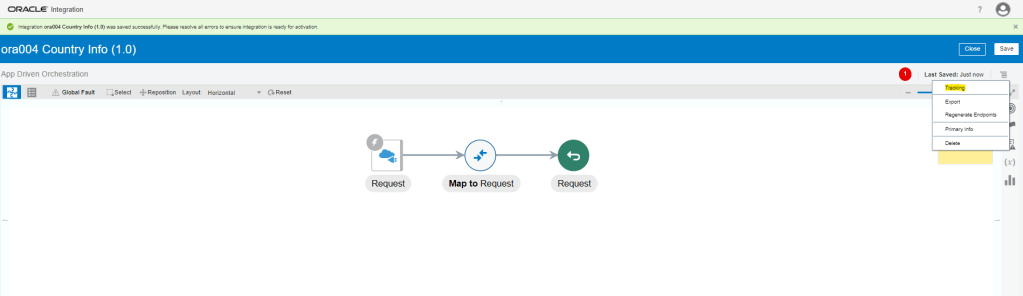
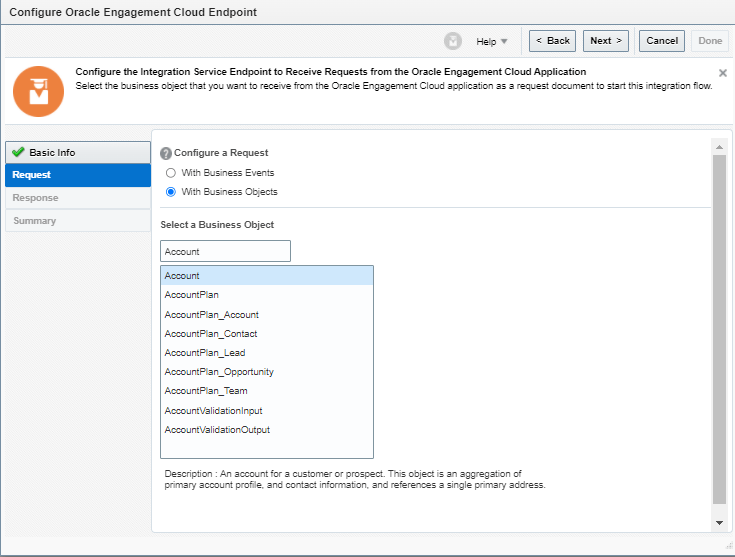
What is Encoding
A machine learning algorithm needs to be able to understand the data it receives. For example, categories such as “small”, “medium”, and “large” need to be converted into numbers. To solve that, we can for example convert them into numeric labels with “1” for small, “2” for medium, and “3” for large.
Different types of Encoding

1. One Hot Encoding
This method is applied to nominal categorical variables.
Example, suppose we have a column containing 7 categorical variables , then in one hot encoding 7columns will be created each for a categorical variable.
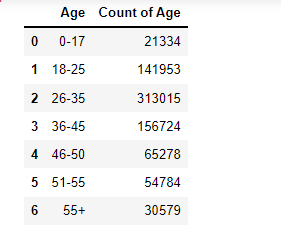
We can encode the Age using python code pd.get_dummies(df_bf_final[‘Age’]) and it will get 7 columns

Dummy Variable Trap : We can drop one column from the set as we can read its value from existing columns. Code to delete is pd.get_dummies(df_bf_final[‘Age’],drop_first=True)
Disadvantage of One -Encoding: It does not make sense to convert categories values into the columns and add to the existing dataset.
Note: If there is a lot of categorical variables in a column then we should not apply this technique.
2. One Hot Encoding with Multiple Categories
In this out of most repeated categories, top 10 categories are selected and they are converted into 9 columns using the Dummy Variable Trap method.
3. Mean Encoding
If we have feature like Zipcode, it will fall under Nominal Category. We cannot use Zipcode directly into machine learning algorithm. We need to convert into numerical variable.
We will use the Output column to and for each categories we will calculate the Mean. This mean values will be used further instead of using zipcode directly

4. Target Guided Ordinal Encoding
In this case we will club the Feature and the output. Then we will take mean of each feature. Once done based on the mean we will assign rank to the feature. Rank can be ascending or Descending order
A has output 1,2,2 so its mean is 1.66. B has output values as 1,4,2 so its Mean is 2.33
Since it is for Ordinal categories, based on Product and Business knowledge we will assign rank to the Mean of each features.
Here A has least mean so it is given rank of 4 which is meant to the least. C has mean value of 3.5 which is highest among all hence given the rank of 1.

5. LABEL Encoding
Part of Ordinal Encoding program, categorical variables are assigned rank based on the the order provided by Business.
If we take categorical variable Education as example we cannot use Education values directly. We need to convert it into numerical values.
We will Label encoding where in Business has provided the ranking of Education. P.H.D stands 1st rank in the list and High School as Rank4.